On this post, a computer shader is executed with
- Dispatch(4,1,1)
- numthreads(3,1,1)
to see what argument values are passed to compute shader main function.
Source code
Project direcory: https://sourceforge.net/p/playpcmwin/code/HEAD/tree/PlayPcmWin/WWDirectCompute12Test2019/
Compute shader: https://sourceforge.net/p/playpcmwin/code/HEAD/tree/PlayPcmWin/WWDirectCompute12Test2019/Sandbox.hlsl
C++ program to run the compute shader: https://sourceforge.net/p/playpcmwin/code/HEAD/tree/PlayPcmWin/WWDirectCompute12Test2019/TestSandboxShader.cpp
Compute shader to run on the GPU
Sandbox.hlsl : this compute shader is called with Dispatch(4,1,1)
RWStructuredBuffer<float> g_output : register(u0);
[numthreads(3, 1, 1)]
void
CSMain(
uint tid : SV_GroupIndex, // 0 <= tid < 3 ← numthreads(3,1,1)
uint3 groupIdXYZ : SV_GroupID) // 0 <= groupIdXYZ.x < 4 ← Dispatch(xyz=(4,1,1))
{
int idx = tid + groupIdXYZ.x * 5;
g_output[idx] = 1;
}
Shader setup
Please refer TestSandboxShader.cpp. It compiles Sandbox.hlsl as a compute shader, prepares GPU buffer of 4096 bytes and sets Unordered Access View, creates compute state, calls Dispatch(4,1,1), and copy GPU buffer memory values to CPU memory of float array.
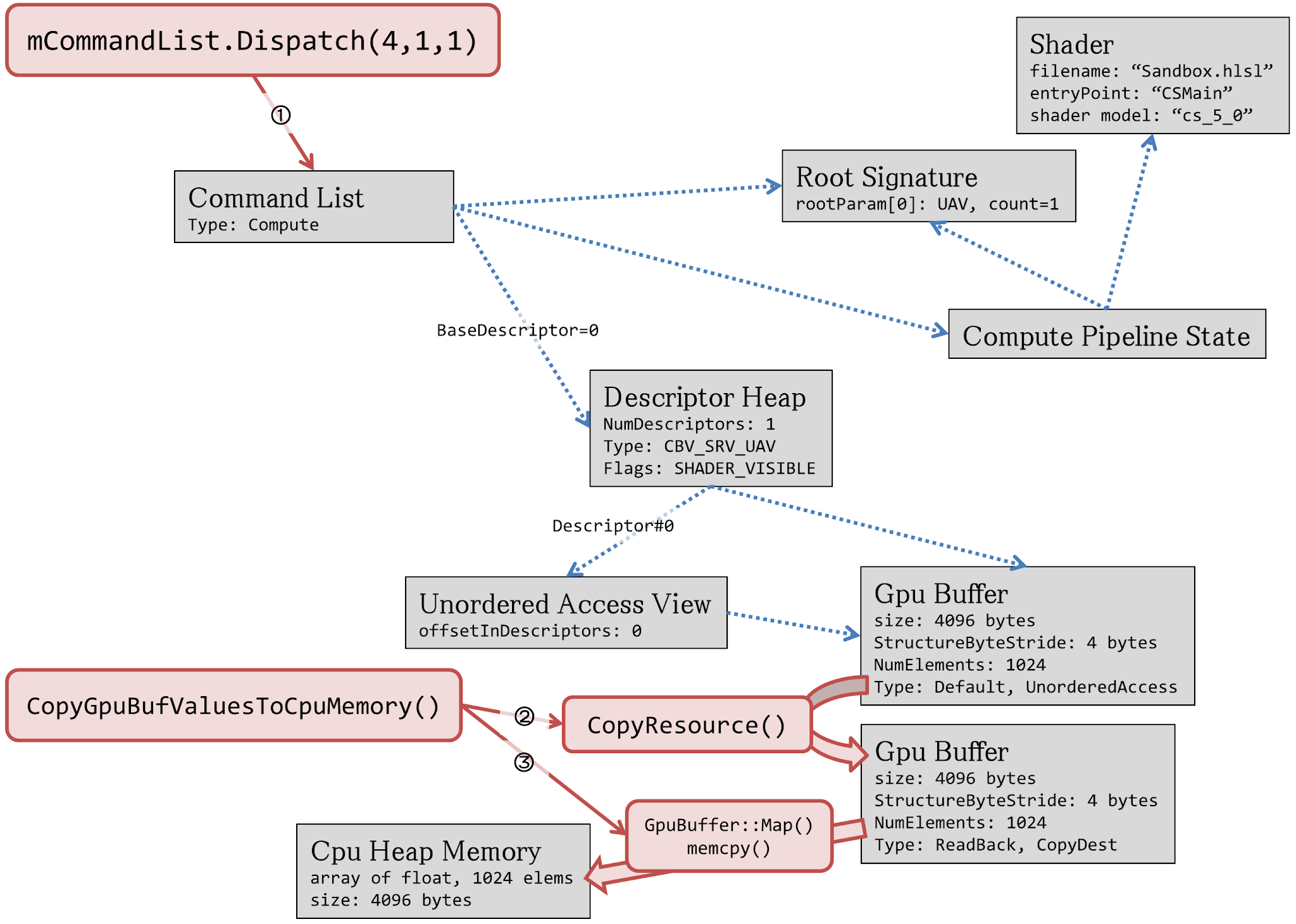
Compute Shader resources, shader main function arguments and thread group
Unordered Access View u0 is visible from the compute shader. Shader can read/write to this buffer.
CSMain function is called 12 times total, function argument of each call is as follows:
CSMain(tid=0, groupIdXYZ=0,0,0)CSMain(tid=1, groupIdXYZ=0,0,0)
CSMain(tid=2, groupIdXYZ=0,0,0)
CSMain(tid=0, groupIdXYZ=1,0,0)
CSMain(tid=1, groupIdXYZ=1,0,0)
CSMain(tid=2, groupIdXYZ=1,0,0)
CSMain(tid=0, groupIdXYZ=2,0,0)
CSMain(tid=1, groupIdXYZ=2,0,0)
CSMain(tid=2, groupIdXYZ=2,0,0)
CSMain(tid=0, groupIdXYZ=3,0,0)
CSMain(tid=1, groupIdXYZ=3,0,0)
CSMain(tid=2, groupIdXYZ=3,0,0)
3 subsequent calls share the same groupIdXYZ and those 3 calls are executed "simultaneously": GPU has several hundred cores. 3 tasks are assigned to 3 individual GPU cores and they runs in parallel (See the following image). On more practical compute shader, it is important to run 128 or more shaders in parallel: something like numthreads(128,1,1) to utilize GPU cores fully.

Those 3 function calls that shares the same groupIdXYZ is called the thread group. GPU function calls of the same thread group can share thread group shared memory (TGSM) that is significantly faster than UAV memory, while TGSM size is limited to 32 KB or so. Utilizing TGSM is one of the key technique to accelerate GPU computation.
On this Sandbox compute shader, each shader writes adjacent GPU memory position simultaneously. This slows down write operation. It is better for each threadgroup threads to write to more remote memory position each other to write data more quickly.
Values written to u0 GPU memory
Sandbox.hlsl shader writes those values to the GPU buffer memory u0:g_Output.
i, g_output[i], Shader function args to write this value0, 1.000000, <== CSMain(tid=0, groupIdXYZ=0,0,0)
1, 1.000000, <== CSMain(tid=1, groupIdXYZ=0,0,0)
2, 1.000000, <== CSMain(tid=2, groupIdXYZ=0,0,0)
3, 0.000000,
4, 0.000000,
5, 1.000000, <== CSMain(tid=0, groupIdXYZ=1,0,0)
6, 1.000000, <== CSMain(tid=1, groupIdXYZ=1,0,0)
7, 1.000000, <== CSMain(tid=2, groupIdXYZ=1,0,0)
8, 0.000000,
9, 0.000000,
10, 1.000000, <== CSMain(tid=0, groupIdXYZ=2,0,0)
11, 1.000000, <== CSMain(tid=1, groupIdXYZ=2,0,0)
12, 1.000000, <== CSMain(tid=2, groupIdXYZ=2,0,0)
13, 0.000000,
14, 0.000000,
15, 1.000000, <== CSMain(tid=0, groupIdXYZ=3,0,0)
16, 1.000000, <== CSMain(tid=1, groupIdXYZ=3,0,0)
17, 1.000000, <== CSMain(tid=2, groupIdXYZ=3,0,0)
18, 0.000000,
19, 0.000000,
20, 0.000000,
21, 0.000000,
22, 0.000000,
23, 0.000000,
24, 0.000000,
No comments:
Post a Comment